Agentic AI in the Enterprise: What Separates Those That Work from Those That Fail

What separates solutions that work from those that fail? Image: Taqtile
By Nix Lopes
During the last two years, the technology industry has been going through the phase in which agentic AI software is moving beyond Proof of Concept (POCs) that overpromise and turning into workflows for real and complex scenarios. High failure rates and frustration accompanied this shift, as already evidenced by the extensively cited MIT State of AI in Business in 2025 study, analyzed in detail by our team in the Taqtile AI Radar 2025.
On the executive side, there is pressure for returns on high investment and great expectations for end-to-end process automation. On the technical side, a growing view is that AI agent software that goes to production doesn't fail due to technology limitations, but from the lack of engineering needed to combine language models with deterministic processes, proper measurement of results, and implementation of methods for agent evolution and learning.
In the first experiments with the technology in industry, the modus operandi was to treat this software as black boxes, expecting results to be generated magically, with quality and accuracy. The bet was on fully autonomous AI systems, language models given total control over the process. At first glance, solutions of this type are tempting for their ease and speed of implementation. However, this method underestimates something intrinsic to the nature of these models: hallucinations.
What the Research Reveals About AI Agents for Business
To understand what separates projects that work from those that fail, a study conducted by researchers from Berkeley, Stanford, and IBM offers one of the most concrete answers to date.
Measuring Agents in Production (MAP) is a systematic survey on production-deployed AI agents. Differentiating itself from previous studies such as MIT NANDA (addressed in an article by Danilo Toledo, co-founder of Taqtile), MAP stands out not only for the volume of cases included, but also for restricting to projects that went to production and for going to the people building and running these systems, rather than executives.
From a questionnaire with four questions, answered by 306 engineers who implement and operate agents on a daily basis, distributed across 26 market niches, the study gathered evidence on which practices are most effective in developing agent-based systems. The questionnaire included the following questions:
What are the applications, users, and requirements of the agents?
What models, architectures, and techniques are used to build agents that go to production?
How are agents evaluated before deployment (going to production)?
What are the main challenges in building agents deployed in production?
The Main Findings
The most prominent finding from MAP was that successful production agents do not have high autonomy. Being deliberately conservative, they rely on human validation during processes (Human-in-the-loop)* to ensure result reliability and learning.
Although 52% of projects use the LLM-as-a-judge* technique, 74% primarily depend on human evaluation. Among the systems studied, 68% execute at most ten steps before requiring human intervention, with half executing fewer than five.
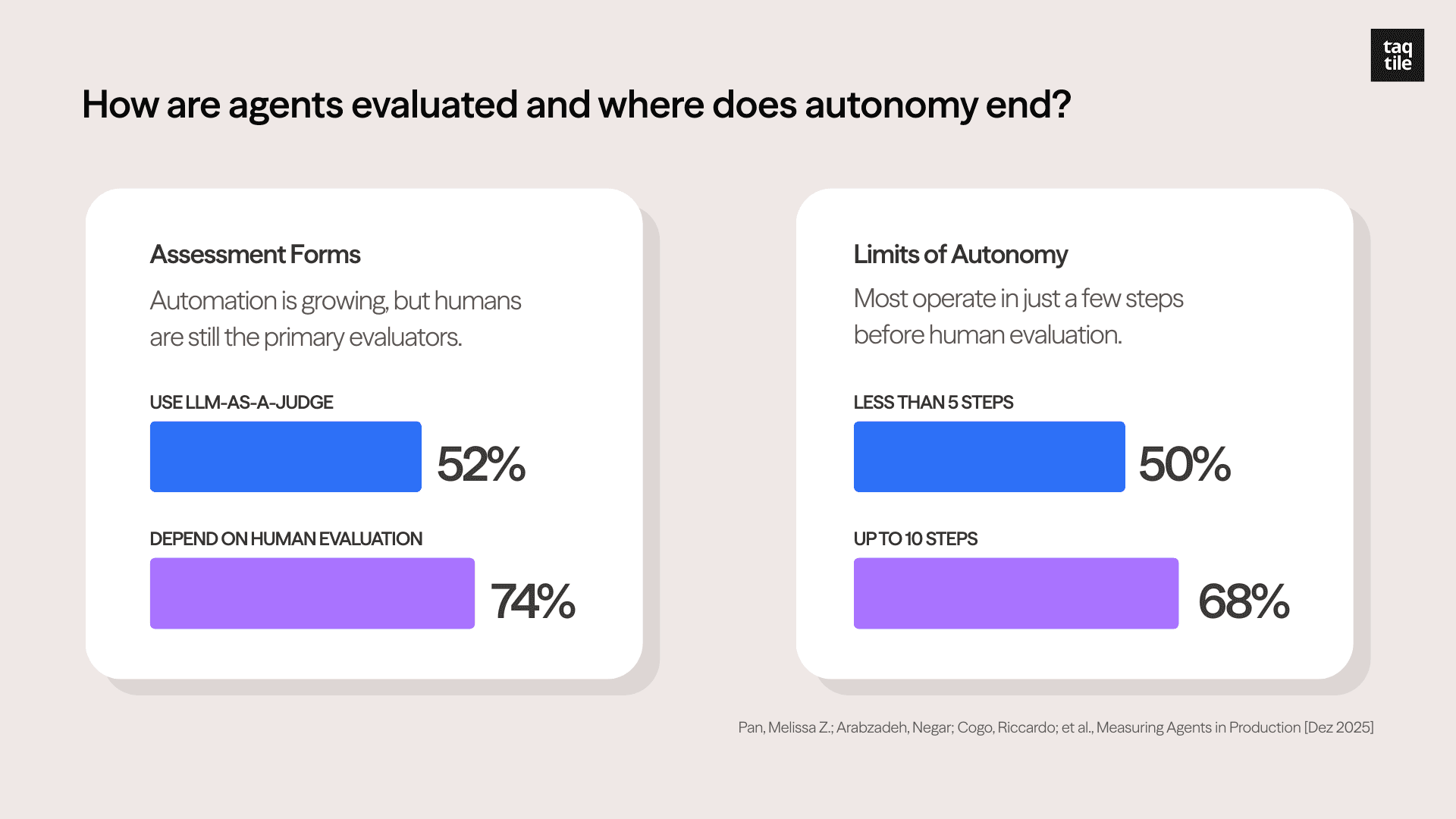
Graphs created by Taqtile. Source: Measuring Agents in Production (Dec 2025)
The study investigated how teams measure the value of delivered products. Most opted for experiments within their own ecosystem, conducting A/B tests, manual feedback, and their own business metrics: such as time per task, rework rate, escalation-to-human rate, cost per resolved case, and impact on operational indicators (SLA, conversion, losses avoided).
They did not rely on ready-made market benchmarks. This reinforces that in the current scenario, "right" and "wrong" are operational and business definitions, not academic ones.
These results echo what MIT NANDA (State of AI in Business in 2025) had already shown: most projects fail because they don't learn from feedback, aren't properly measured, don't fit into real business flows, and aren't reliable because sensitive processes are executed in a non-deterministic way.
Another notable result is that 70% of projects use ready-made models without fine tuning*, focusing only on Prompt Engineering*. The study also mapped the low adoption of ready-made agent frameworks: 85% of cases built custom applications to gain control and predictability. Regarding the balance between output quality and response time, 66% of participants chose to prioritize quality, even if that meant waiting minutes for a response.
The Success Conditions for AI-Driven Process Automation
The research points to conditions where agents have the greatest potential to deliver results in production:
there are repetitive tasks with high human cost; 73% of respondents developed agents for manual task automation and efficiency gains.
there is a verifiable "operational truth," even if partial.
the process accepts human-in-the-loop as a control step.
The study also provided information about the market niches in which systems were deployed, and examples of applications. We included the chart and table below for better consolidation and visualization of the information:
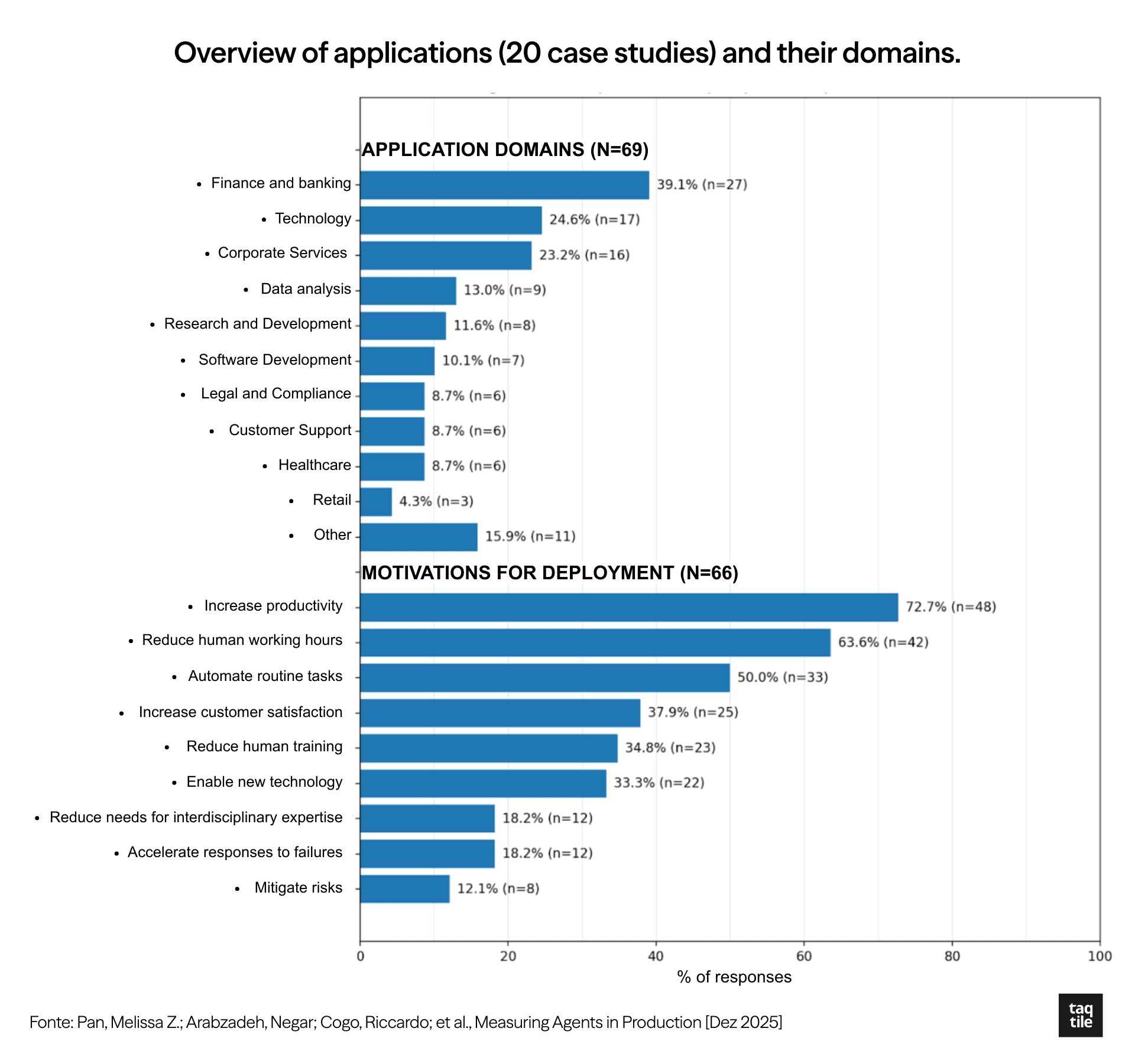

Graph and table created by Taqtile. Source: Measuring Agents in Production (Dec 2025)
The field is still consolidating, but MAP data on enterprise AI agents shows that the direction is clearer than it seems: less autonomy, more control; less benchmark, more proprietary measurement; less ready-made framework, more custom engineering. Companies that understand this first have a real advantage, not over the technology, but over how to use it.
This article is part of Taqtile's initiative to share what we are learning as we develop AI agent software. This is a topic we follow closely. On our page, you'll find more on this subject from the perspective of those who build: experiments, real cases, and reflections on AI in the enterprise, from those who build in practice. Follow us at @Taqtile.
For companies looking to structure this journey methodically, the AI Sprint is our approach — a design sprint adapted for the generative AI era.
If you want to explore how these learnings apply to your context, get in touch with our team.
Footnotes:
LLM-as-a-judge: use of an LLM to evaluate the system's responses/outputs.
Human-in-the-loop: a flow in which humans validate/take over critical steps (e.g., final approval, exceptions), reducing risk and increasing reliability in production.
Prompt engineering: building/iterating instructions in the prompt and context to guide the model.
Fine tuning: adjusting model weights with proprietary data.
References
Pan, Melissa Z.; Arabzadeh, Negar; Cogo, Riccardo; et al., Measuring Agents in Production [Dec 2025]
The GenAI Divide (MIT NANDA), State of ai in business 2025 report
Alvarez-Teleña, S.; Díez-Fernández M., Advances in Agentic AI: Back to the Future [Dec, 2025]