Inteligência Artificial e agentes nas empresas: o que separa os que funcionam dos que falham

O que separa as soluções que funcionam das que falham? Imagem: Taqtile
Por Nix Lopes
Durante os últimos dois anos, a indústria de tecnologia vem passando pela fase em que softwares com agentes de IA estão deixando de ser Prova de Conceito (POCs) que vendem sonhos e virando workflows de cenários reais e complexos. Altas taxas de falha e frustração acompanharam essa mudança, como já evidenciado pelo extensamente citado estudo MIT State of AI in Business in 2025, analisado em detalhe pelo nosso time no Radar AI Taqtile 2025.
Do lado executivo, existe a pressão por retorno do alto investimento e grande expectativa na automação de processos de ponta a ponta. Do lado técnico, cresce a visão de que os softwares com agentes de IA que sobem em produção não falham por limitação da tecnologia, mas pela falta da engenharia necessária para mesclar o uso dos modelos de linguagem com processos determinísticos, da mensuração correta dos resultados e da implementação de métodos de evolução e aprendizados dos agentes.
Nos primeiros experimentos com a tecnologia na indústria, o modus operandi era tratar esses softwares como caixas-pretas, na expectativa dos resultados serem gerados magicamente, com qualidade e assertividade. Assim, os modelos de linguagem ganharam total autonomia. Em primeira análise, soluções do tipo são tentadoras pela facilidade e velocidade de implementação. Porém, esse método subestima algo intrínseco da natureza desses modelos: as alucinações.
Modelos de linguagem nada mais são que modelos probabilísticos, possuindo porcentagens de acerto e falha. Nesse contexto, o desafio atual que cabe aos engenheiros de software resolverem é encontrar métodos para aproveitar os benefícios da tecnologia, contornando suas limitações. Algo ainda mais importante quando aplicada em um cenário real com centenas de variáveis, dados sensíveis e usuários de diferentes perfis, onde erros podem custar caro ao negócio.
O que pesquisas revelam sobre agentes de IA
Para entender o que separa os projetos que funcionam dos que falham, um estudo conduzido por pesquisadores de Berkeley, Stanford e IBM oferece uma das respostas mais concretas até o momento.
O Measuring Agents in Production (MAP) é um levantamento sistemático sobre agentes de IA implantados em produção. Diferenciando-se de estudos anteriores como o MIT NANDA (abordado em artigo pelo Danilo Toledo, cofundador da Taqtile), o MAP se destaca não só pelo volume de casos incluídos, mas também pela restrição a projetos que foram para produção e por entrevistar os engenheiros em vez dos executivos.
A partir de um questionário com quatro perguntas, respondido por 306 engenheiros que implementam e operam agentes no dia a dia, distribuídos por 26 nichos de mercado, o estudo reuniu indícios sobre quais práticas são mais eficazes no desenvolvimento de sistemas baseados em agentes. O questionário incluiu as seguintes perguntas:
Quais são as aplicações, os usuários e os requisitos dos agentes?
Quais modelos, arquiteturas e técnicas são usados para construir agentes que vão para produção?
Como os agentes são avaliados antes do deploy (entrada em produção)?
Quais são os principais desafios na construção de agentes implantados em produção?
Os principais achados
O achado de maior destaque do MAP foi que os agentes em produção que obtiveram sucesso não possuem alta autonomia. Sendo propositalmente conservadores, recorrem à validação humana durante os processos (Human-in-the-loop)* para garantir a confiabilidade dos resultados e o aprendizado.
Embora 52% dos projetos utilizem a técnica LLM-as-a-judge*, 74% dependem primariamente de avaliação humana. Entre os sistemas estudados, 68% executam no máximo dez passos antes de exigir intervenção humana, com metade executando menos de cinco.

Gráficos elaborados pela Taqtile. Fonte: Measuring Agents in Production (Dez 2025)
O estudo investigou como as equipes medem o valor dos produtos entregues. A maioria optou por experimentos dentro do próprio ecossistema, realizando testes A/B, feedback manual e metrificações próprias do negócio, como tempo por tarefa, taxa de retrabalho, taxa de escalonamento para humano, custo por caso resolvido, e impacto em indicadores operacionais (SLA, conversão, perdas evitadas).
Ou seja, não se basearam em benchmarks prontos de mercado. Isso reforça que no cenário em que estamos, "certo" e "errado" são definições operacionais e de negócio, não acadêmicas.
Esses achados se alinham com o que o MIT NANDA (State of AI in Business in 2025) já evidenciava: a maioria dos projetos morre porque não aprende com feedback, não é metrificada corretamente, não se encaixa no fluxo real dos negócios e não é confiável por ter processos sensíveis executados de forma não determinística.
Outro resultado de destaque é que 70% dos projetos usam modelos prontos, sem fine tuning*, focando apenas em Prompt Engineering*. O estudo também mapeou a baixa adesão de frameworks de agentes prontos: 85% dos casos construíram aplicações customizadas para ganhar controle e previsibilidade. Em relação ao balanço entre qualidade dos outputs e tempo de resposta, 66% dos participantes optaram por priorizar a qualidade, mesmo que isso significasse um tempo de resposta na casa dos minutos.
As condições de sucesso para automação de processos com IA
A pesquisa aponta as condições em que agentes têm maior potencial de gerar resultados em produção:
há tarefas repetitivas com custo humano alto; 73% dos entrevistados desenvolveram agentes para automatização de tarefas manuais e aumento de eficiência.
existe uma "verdade operacional" verificável, mesmo que parcial.
o processo aceita human-in-the-loop como etapa de controle.
O estudo também trouxe informações sobre os nichos de mercado em que os sistemas foram implantados, e exemplos de aplicações. Trouxemos o gráfico e a tabela abaixo para uma melhor consolidação e visualização das informações:
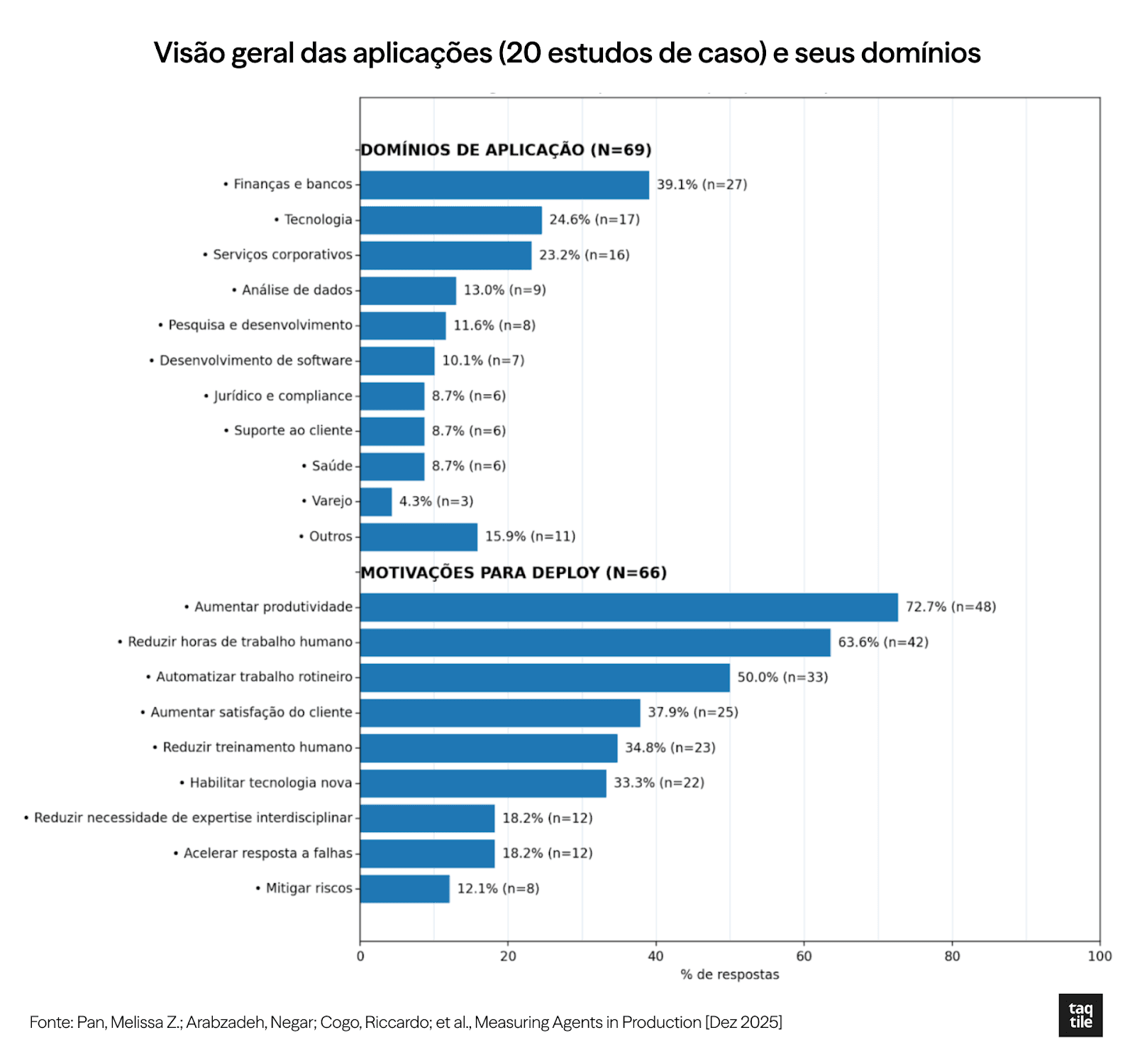
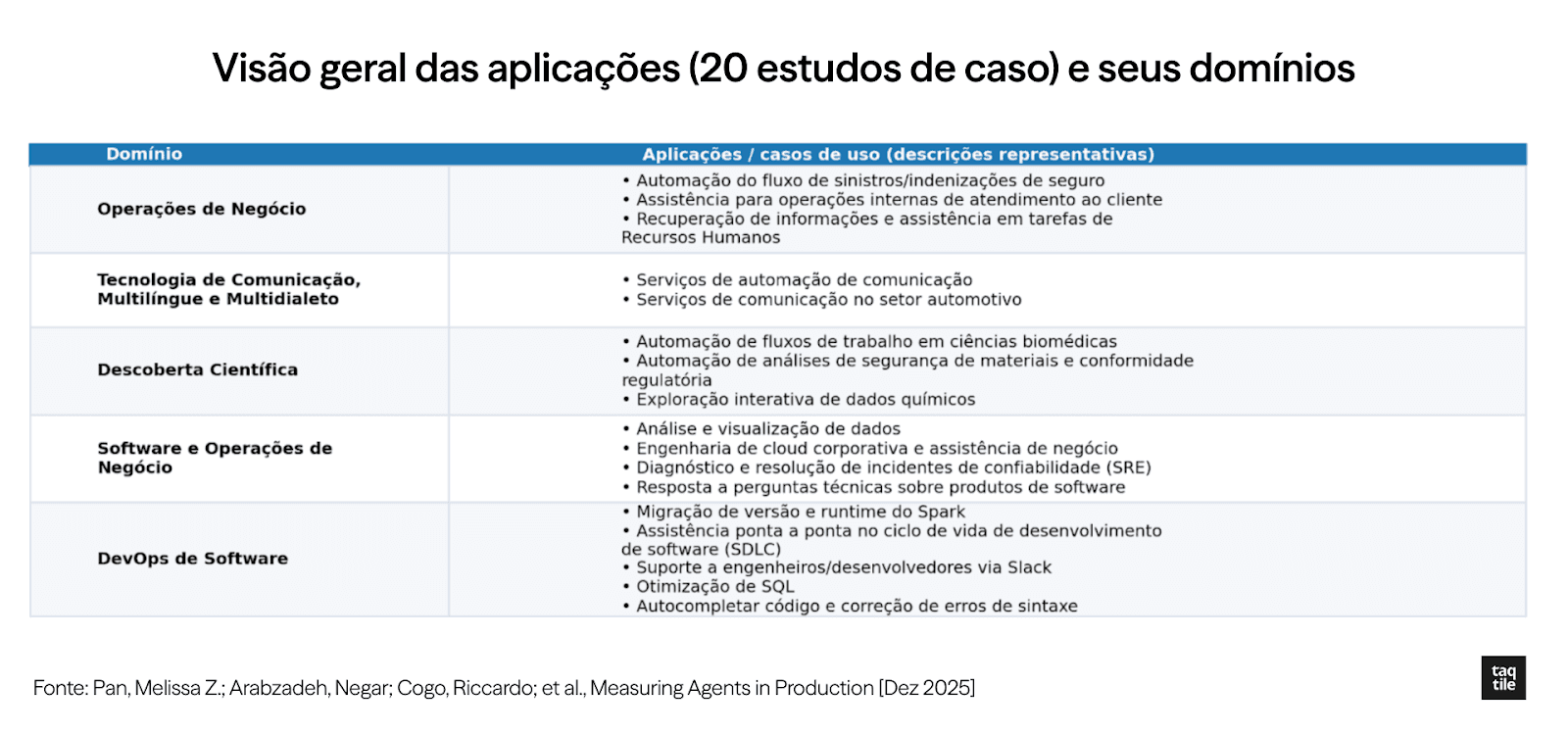
Gráfico e tabela elaborados pela Taqtile. Fonte: Measuring Agents in Production (Dez 2025)
O campo ainda está se consolidando, mas os dados do MAP mostram que a direção está mais clara do que parece: menos autonomia, mais controle; menos benchmark, mais metrificação própria; menos framework pronto, mais engenharia customizada. Empresas que entenderem isso antes têm vantagem real, não sobre a tecnologia, mas sobre como usá-la.
Esse artigo faz parte de uma iniciativa da Taqtile em compartilhar o que estamos aprendendo ao desenvolvermos softwares com agentes de IA. Esse é um tema que acompanhamos bastante aqui. Em nossa página no LinkedIn, você encontra mais sobre esse assunto do ponto de vista de quem está construindo casos reais de aplicação de IA nas empresas.
Para empresas que querem iniciar essa jornada com método, o AI Sprint é nossa metodologia de design sprint adaptado para a era de IA generativa. E se quiser explorar como esses aprendizados podem se aplicar ao seu contexto, fale com o nosso time.
Notas de rodapé:
LLM-as-a-judge: uso de um LLM para avaliar respostas/saídas do sistema.
Human-in-the-loop: fluxo em que humanos validam/assumem etapas críticas (ex.: aprovação final, exceções), reduzindo risco e aumentando confiabilidade em produção
Prompt engineering: construção/iteração de instruções no prompt e contexto para guiar o modelo
Fine tuning: ajustar pesos do modelo com dados próprios
Referências
Pan, Melissa Z.; Arabzadeh, Negar; Cogo, Riccardo; et al., Measuring Agents in Production [Dez 2025]
The GenAI Divide (MIT NANDA), State of ai in business 2025 report
Alvarez-Teleña, S.; Díez-Fernández M., Advances in Agentic AI: Back to the Future [Dez, 2025]